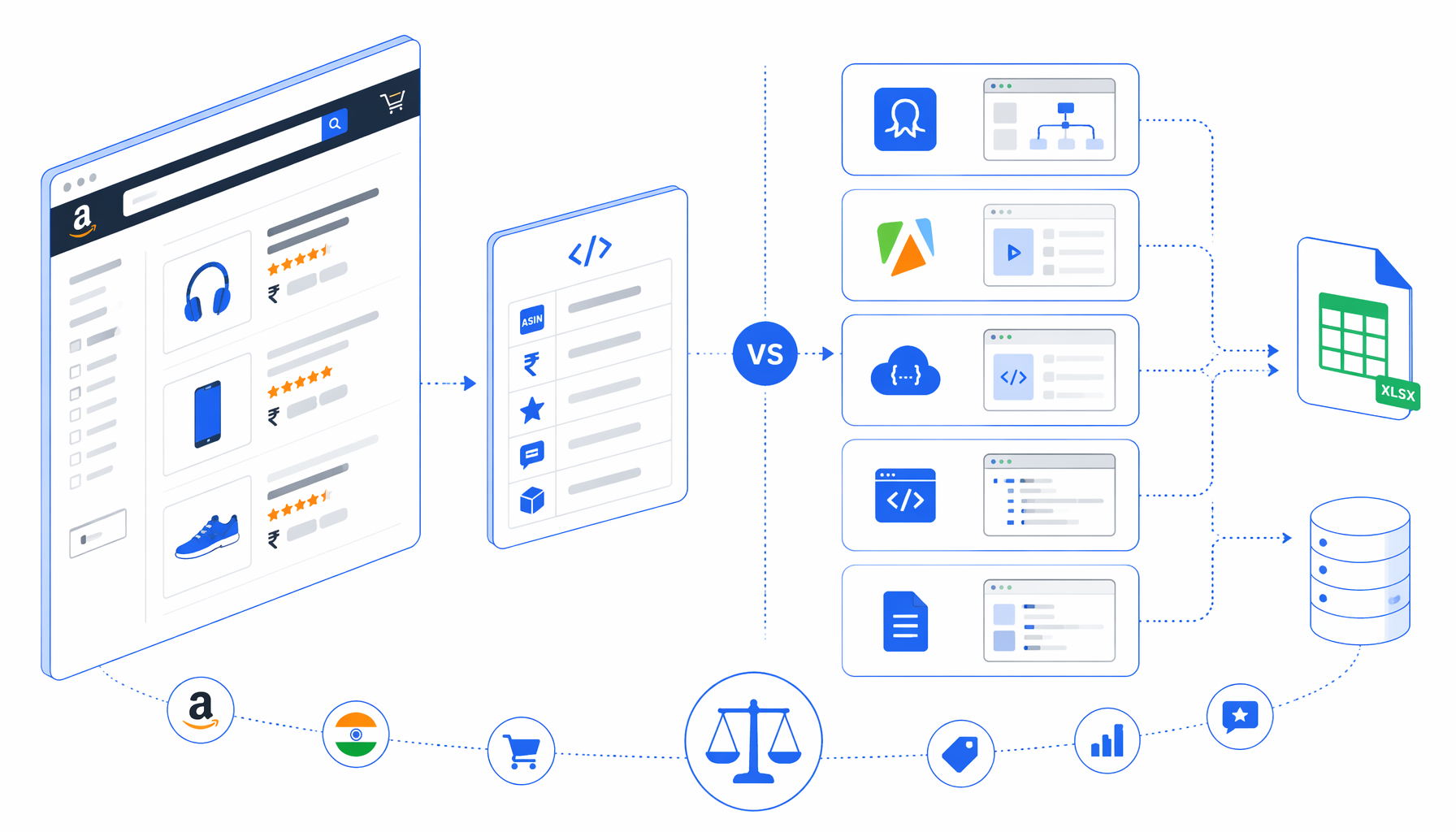
The best Amazon product scraper for India is not always the biggest cloud platform. For Amazon.in listing research, choose by where the browser runs, whether code is acceptable, how pricing is metered, and whether the output needs to be a reviewable CSV. This comparison covers Octoparse, Apify, scraper APIs, scripts, and UScraper's Amazon India Product Scraper template.
Decision frame
How to compare Amazon India product data extraction tools
An Amazon India scraper alternative should be judged by the job it has to finish, not by a demo that returns ten products once. Amazon.in search pages vary by keyword, category, location, session state, sponsored modules, availability, and anti-abuse screens. A useful workflow preserves enough context for someone else to understand each row later.
Searches like how to scrape Amazon India products fall into five practical lanes:
- Approved API access for eligible affiliate, seller, or product-data use cases.
- No-code SaaS scrapers such as Octoparse for hosted visual setup.
- Marketplace actors such as Apify for datasets, APIs, and cloud automation.
- Scraper APIs such as Bright Data, Oxylabs, or ScrapingBee for request handling and scale.
- Local desktop workflows such as UScraper when operators want visible flow editing and local CSV.
Do not compare these options only by "can it scrape Amazon?" Compare hosting, code ownership, cost meter, output format, compliance path, and who fixes the selectors when Amazon changes the page.
Side-by-side
Amazon India scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Amazon-approved API route | Eligible affiliate, seller, or product integrations | Amazon API | Medium | Structured API response | Eligibility and API terms | Strong compliance path, slower spreadsheet setup |
| Octoparse Amazon India template | Hosted no-code visual scraping | Vendor cloud | Low | Cloud CSV/Excel export | SaaS plan and task limits | Fast start, less local custody |
| Apify Amazon product actors | Recurring cloud jobs and APIs | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Credits plus runtime usage | Strong automation, platform-hosted storage |
| Bright Data Amazon scraper | Enterprise managed extraction | Vendor infrastructure | Low to medium | API or managed data | Usage or dataset pricing | Powerful, often heavy for one CSV |
| Oxylabs Amazon Scraper API | Developers using an e-commerce API | Vendor infrastructure | Medium | API responses | API usage pricing | You own storage and QA |
| ScrapingBee Amazon API | Developers adding scraping to code | API provider | Medium | API response | Request/API usage pricing | Not a visual analyst workflow |
| DIY Python or Node scripts | Engineering-owned parsers | Your machines or servers | High | Whatever you build | Engineering time plus infra | Full control, full maintenance |
| UScraper + Amazon India Product Scraper | Local CSV from controlled Amazon.in listing pages | Local desktop app | Low | CSV with listing fields | Free template; app license applies | Inspectable local runs, not fleet-scale scraping |
This is not a universal ranking. Product platforms may prefer an API provider. Data teams may prefer Apify or scripts. A marketplace analyst who needs a controlled Amazon.in keyword export to CSV may prefer UScraper.
Apify vs Octoparse
Apify vs Octoparse Amazon scraper: where UScraper fits
The common Apify vs Octoparse Amazon scraper comparison is really a workflow question. Apify is strongest when the scraper belongs inside a broader automation system: scheduled runs, APIs, datasets, retries, and developer handoff. Octoparse is strongest when business users want a hosted visual scraper and cloud exports without building an actor.
UScraper sits in a different lane. The Amazon India Product Scraper template is an importable workflow graph. It opens Amazon.in search-result URLs, waits for result cards, checks for the lightweight "Continue shopping" validation page, clicks the visible validation button when present, and appends product rows to CSV.
UScraper wins when input URLs, browser state, and CSV output should stay in a local desktop app workflow.
Apify, Octoparse, and scraper APIs win for remote scheduling, API orchestration, shared datasets, and managed retries.
UScraper wins when operators need Navigate, Wait, Click, Structured Export, and Loop Continue blocks in one editable flow.
Hosted providers win for high concurrency, proxy fleets, SLA-backed delivery, and programmatic feeds.
Output fit
What the UScraper Amazon India template exports
The bundled workflow is preconfigured for lightning cable and Amazon.in search-result pages 1-20. Replace the keyword URLs before running it. The target is listing-level research, not deep product-detail enrichment.
| CSV column | What it captures | Why it matters |
|---|---|---|
keyword | Search keyword from the URL | Ties rows to the query |
asin | Product ASIN | Helps deduplicate rows |
title | Visible product title | Main assortment field |
detail_page_url | Product URL | Keeps source traceability |
star_rating | Visible rating text | Supports quality filters |
number_of_reviews | Review or rating count | Prioritizes high-signal products |
price | Visible listing price | Supports price checks |
current_time | Scrape timestamp | Helps compare repeated exports |
The workflow shape is auditable: Set Window Size -> Navigate -> Wait -> Continue Shopping Check -> Wait for Product Rows -> Structured Export -> Loop Continue. Structured Export uses row selectors and JavaScript columns for field extraction.
If the final artifact is a spreadsheet for product research, price checks, or keyword analysis, a local workflow with explicit columns is often enough.
Compliance
Legal and operational guardrails
Amazon.in's Conditions of Use and robots directives can restrict automated collection. Public visibility in a browser is not the same as permission for unrestricted extraction.
Keep the guardrails practical:
- Prefer Amazon-approved API access when your use case qualifies.
- Do not bypass CAPTCHA, login walls, payment flows, or access controls.
- Keep runs modest and collect only fields you need.
- Validate output quality before pricing, inventory, or commercial decisions.
For examples, browse the UScraper template library or the UScraper blog.
FAQ
FAQ
What is the best Amazon product scraper for India?
Use official Amazon API routes when eligible, hosted actors or scraper APIs for recurring programmatic work, scripts when engineers own the stack, and UScraper when you need an inspectable local desktop app workflow that exports Amazon.in listing rows to CSV.
How does UScraper compare with Octoparse for Amazon India scraping?
Octoparse is a hosted no-code scraper with Amazon templates and cloud exports. UScraper runs the imported workflow locally, keeps browser actions and selectors visible, and writes amazon-product-listing-scraper-for-india.csv to your configured folder.
Should I use Apify, Bright Data, Oxylabs, ScrapingBee, or UScraper?
Use Apify, Bright Data, Oxylabs, or ScrapingBee for cloud execution, APIs, scheduling, proxy infrastructure, retries, or recurring jobs. Use UScraper when the operator wants an inspectable Amazon.in keyword listing export to CSV.
Is it legal to scrape Amazon India product listings?
Amazon.in pages may be visible in a browser, but automated collection can still be limited by Amazon conditions of use, robots directives, anti-abuse systems, intellectual property rights, privacy rules, and local law. Review current rules and get legal advice before commercial reuse.
What does the UScraper Amazon India listing template export?
The companion template exports keyword, asin, title, detail_page_url, star_rating, number_of_reviews, price, and current_time into amazon-product-listing-scraper-for-india.csv. Start from the Amazon India Product Scraper template, replace the sample keyword URLs, and run a small test first.