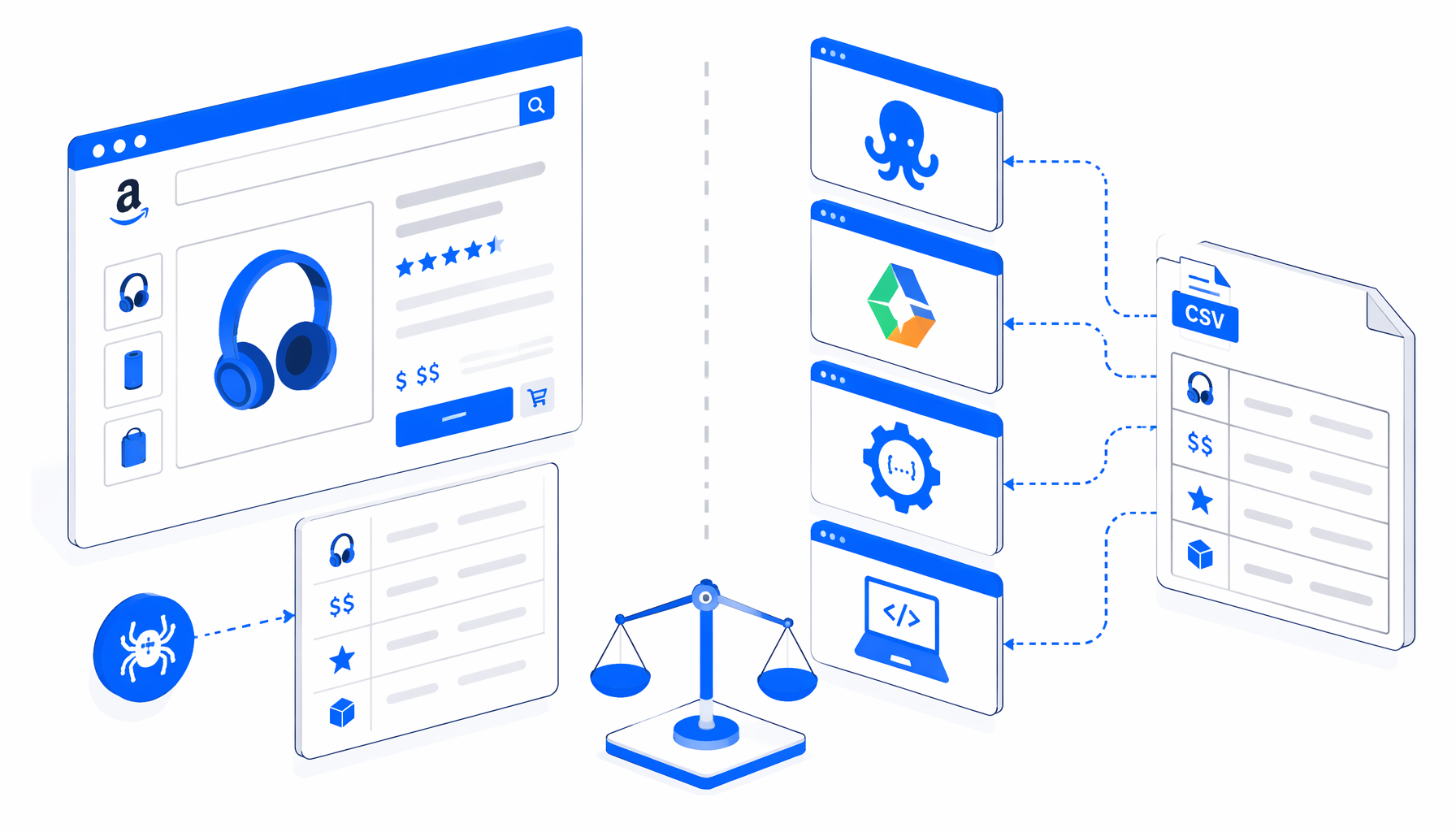
The best Amazon product scraper depends on the job. A seller checking twenty ASINs needs a different workflow than an engineering team feeding a live pricing system. This comparison looks at Octoparse, Apify, scraper APIs, scripts, official API routes, and UScraper's Amazon Product Details Scraper US for local CSV export.
Comparison frame
Amazon product scraper alternatives compared
Amazon product pages are not simple catalog records. Title, brand, price, availability, seller, review count, category path, bullets, rank, and images can appear in separate modules that change by location, account state, product type, and availability.
Most teams choose among official API routes, marketplace actors, no-code SaaS scrapers, scraper APIs, custom scripts, and local desktop workflows where the block graph is visible and the CSV is written locally.
The practical question is not "which vendor says Amazon scraper?" It is "which workflow produces rows your team can afford, explain, maintain, and use legally?"
Side-by-side
Best Amazon product scraper options by workflow
| Option | Best fit | Hosting | Code | Output | Pricing model | Main trade-off |
|---|---|---|---|---|---|---|
| Amazon Product Advertising API | Approved affiliate apps, item lookup, commerce integrations | Amazon API | Developer | API responses | API access and eligibility rules | Most sanctioned route, but not a quick spreadsheet scraper |
| Octoparse Amazon Product Scraper | No-code teams that prefer hosted visual scraping | Vendor cloud | Low | CSV, Excel, cloud task output | Free tier plus paid SaaS plans and task limits | Easy setup, less local custody |
| Apify Amazon Product Scraper | Hosted actors, datasets, API-driven scraping jobs | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform credits, actor pricing, and runtime usage | Strong orchestration, but rows live in a cloud workflow |
| Bright Data, Oxylabs, ScraperAPI, Rainforest API | Managed extraction, proxies, JSON delivery, larger jobs | Vendor infrastructure | Medium | Structured API responses | Request, result, plan, or dataset metering | Strong infrastructure, more pricing and vendor complexity |
| ParseHub-style visual scrapers | Generic no-code extraction projects | Vendor cloud | Low | CSV, JSON, integrations | Tiered SaaS | Flexible, but page changes still require maintenance |
| Python, Playwright, Scrapy scripts | Engineering-owned pipelines and custom parsing | Your infrastructure | High | Whatever you build | Engineering time plus proxy/API cost | Maximum control, maximum maintenance |
| UScraper + Amazon Product Details template | Local CSV from a controlled ASIN or product URL list | Local desktop app | Low | CSV with ASIN, title, price, seller, ratings, bullets, images | Free template; app licensing applies | Best for inspectable local runs, not fleet-scale cloud scraping |
Where UScraper wins
When UScraper is the better Amazon scraper alternative
UScraper is a strong fit when the input is already known: a reviewed list of Amazon.com /dp/{ASIN} or /gp/product/{ASIN} URLs. The companion Amazon Product Details Scraper US template opens each product page, waits for it to load, checks that #productTitle exists, and appends one row to CSV only when the page looks like a product detail page.
The JSON workflow is the source of truth:
Set Window Size -> Navigate -> Wait for Page Load -> Sleep
-> Element Exists (#productTitle) -> Structured Export -> Loop Continue
Structured Export writes amazon-produits-details-scraper-via-asin-us.csv with append mode. Columns include asin, title, brand, price, currency, rating, review_count, availability, seller, category, bullet_points, best_sellers_rank, image_url, and product_url.
UScraper wins when ASIN lists, browser sessions, and CSV files should stay in a local desktop app workflow.
Hosted tools win when you need remote schedules, queues, retries, API triggers, proxy pools, and always-on collection.
UScraper wins when analysts need to inspect title checks, prices, seller text, availability, and image selectors.
Official API routes win when you need contractual rights, affiliate metadata, documented resources, and approved reuse.
Where cloud wins
When Apify, Octoparse, APIs, or scripts make more sense
Choose Apify for hosted actors, run history, datasets, API access, and programmatic orchestration. Choose Octoparse when a non-technical team wants a hosted visual scraper and cloud task management. Choose Bright Data, Oxylabs, ScraperAPI, or Rainforest API when the deliverable is structured JSON through an API with geotargeting, retries, proxy management, or vendor support. Choose custom scripts when engineers need versioned parsers, tests, queues, storage, and exact fallback behavior.
Prefer UScraper for a reviewable .csv from known product URLs. Prefer scraper APIs when downstream systems need JSON, webhooks, or automated ingestion.
Policy fit
Do not skip Amazon policy and API review
Amazon product pages can be visible in a browser, but automated collection can still be restricted by Amazon's Conditions of Use, robots.txt, anti-abuse systems, copyright, privacy rules, and local law. Do not bypass CAPTCHA, login walls, payment flows, or access controls.
For approved affiliate and commerce integrations, compare every scraper with Amazon's Product Advertising API documentation and the GetItems operation. Browser workflows are useful for supervised research, not contractual reuse.
Decision guide
Which Amazon product data extraction tool should you pick?
Pick Amazon Product Advertising API for approved item lookup and affiliate integration. Pick Apify for hosted actors and developer-friendly datasets. Pick Octoparse for hosted no-code scraping. Pick Bright Data, Oxylabs, ScraperAPI, or Rainforest API for managed API delivery. Pick custom scripts when engineers own the pipeline.
Pick UScraper when the job is narrower and CSV-first: import the template, replace the sample URLs, run a small validation batch, and audit rows locally. Start from the Amazon Product Details Scraper US template, read the Amazon product scraping tutorial, or browse the UScraper template library.
FAQ
What is the best Amazon product scraper?
Use Product Advertising API for approved affiliate or commerce integrations, hosted actors or scraper APIs for recurring cloud pipelines, no-code SaaS for visual scraping, scripts for engineering control, and UScraper for local CSV from known Amazon.com product URLs.
How do Octoparse and Apify compare for Amazon product scraping?
Octoparse is a hosted no-code scraper environment. Apify is stronger for hosted actors, datasets, API calls, and developer automation. UScraper runs an inspectable local desktop workflow and writes CSV from your ASIN URLs.
When should I use an Amazon scraper API instead?
Use a scraper API or managed provider when you need structured JSON, API orchestration, high volume, geotargeting, retries, proxy management, or vendor support. Use local CSV for supervised batches.
What does the UScraper Amazon Product Details Scraper export?
The companion template exports asin, title, brand, price, currency, rating, review_count, availability, seller, category, bullet_points, best_sellers_rank, image_url, and product_url. It checks #productTitle before export.
Is it legal to scrape Amazon product details?
Amazon product pages may be visible in a browser, but automated collection can still be limited by terms, robots directives, anti-abuse systems, intellectual property rights, privacy rules, and local law. Avoid bypassing access controls or CAPTCHA, and get legal review before commercial reuse.