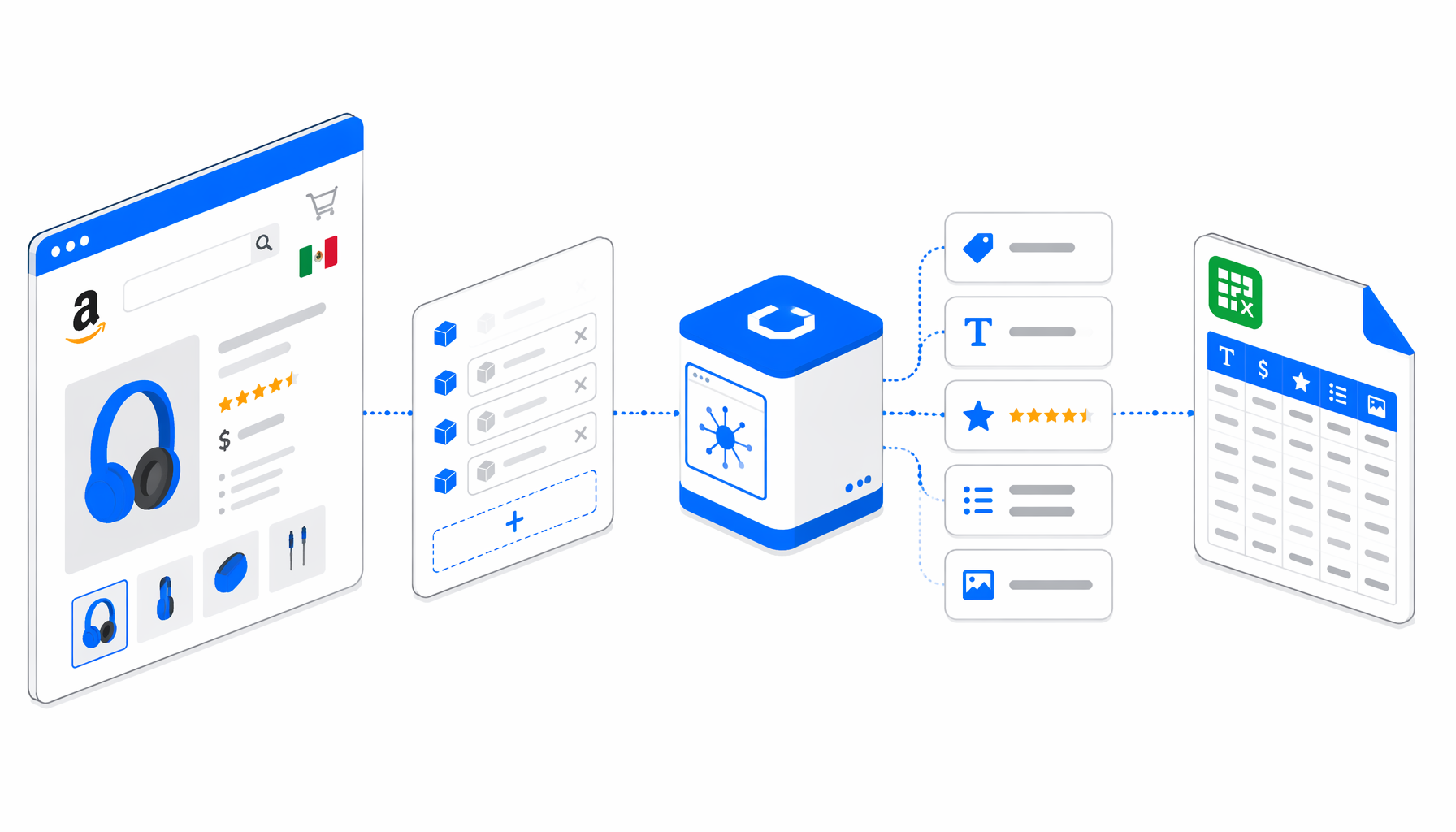
This tutorial shows how to scrape Amazon Mexico product details into CSV with the Amazon Mexico Product Detail Scraper template for UScraper. You will prepare ASIN URLs, import the workflow, set the export path, run a small batch, and validate the exported rows before using them downstream.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a reviewed list of Amazon.com.mx product detail URLs, and a folder where CSV exports can be written. Use direct product URLs such as https://www.amazon.com.mx/dp/B0DG93MZCR; this workflow is for detail pages, not search discovery, cart pages, account data, or checkout flows.
Start with two or three URLs. Amazon pages vary by language, region, availability, session state, category, and anti-abuse controls. A small run confirms that the CSV matches the browser.
Compliance first: review source terms, Amazon.com.mx robots directives, marketplace policies, privacy rules, and your intended use before automation. Do not bypass CAPTCHA, login walls, or other access controls.
Workflow anatomy
How the Amazon Mexico product scraper works
The JSON export is the authoritative sample of the workflow definition. Its block sequence is intentionally short: Navigate -> Wait for Page Load -> Wait for Element -> Inject JavaScript -> Structured Export -> Loop Continue.
Navigate owns the ASIN URL list. Wait for Page Load gives the page time to settle. Wait for Element checks for #productTitle so the workflow does not export too early. Inject JavaScript gathers normalized values from product modules, detail labels, image elements, and the current URL. Structured Export maps those values into CSV columns. Loop Continue advances to the next URL.
| Workflow step | What to check | Why it matters |
|---|---|---|
| Navigate | Your approved Amazon.com.mx detail URLs | One input URL should become one product row. |
| Wait for Element | #productTitle stays enabled | Prevents blank rows caused by premature extraction. |
| Inject JavaScript | Field names match the template export | This is where title, price, rating, bullets, rank, and images are collected. |
| Structured Export | File name, folder, headers, append mode | Keeps repeated runs organized and spreadsheet-ready. |
Runbook
Scrape Amazon product details to CSV
Import the template
Open the related template page, download the JSON, and import it into UScraper.
Replace the sample ASIN URLs
In Navigate, paste the Amazon.com.mx product detail URLs your team has reviewed and is allowed to process.
Keep the page waits
Keep the 45-second page-load wait and the visible #productTitle check. These waits are part of the extraction quality control.
Confirm the export path
In Structured Export, verify amazon_mx_detalles_scraper.csv, headers, append mode, and the save folder before running a real batch.
Run, inspect, then scale
Run two or three products first, compare the CSV against the browser, then add more ASIN URLs only after the output looks correct.
There is no bundled CSV sample, so your first run is the sample. Keep it small and label it clearly. Append mode adds rows to an existing file; use a clean folder when you want a fresh test.
Output
What the Amazon product details export includes
The template is built for product research, catalog QA, and competitor monitoring where one row per ASIN is easier to inspect than raw HTML or nested JSON.
| Field group | CSV columns |
|---|---|
| Product identity | asin, web_page_url, title, brand, item_model_number |
| Commerce signals | price, inventory, color, date_first_available |
| Ratings and rank | star_rating, number_of_reviews, best_sellers_rank |
| Product content | bullet_points, product_description, product_dimensions |
| Images and audit | image_url_1 through image_url_6, current_time |
Use the file in Excel, Google Sheets, BI tools, pricing review sheets, SKU enrichment workflows, or QA scripts. Keep web_page_url and current_time so reviewers can trace rows back to the source page and run date.
Validation
Validate prices, images, and blank fields
Treat validation as part of the scraping process. Open the CSV beside the browser and check rows from the beginning, middle, and end of the run. Product pages can change based on inventory, category, language, promotions, or prompts.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty title | Product title never rendered or a challenge page loaded | Handle prompts, rerun one URL, and keep the title wait enabled. |
Blank price | Product unavailable, member-only display, category variation, or price module changed | Check the page manually and treat blank price as a review flag. |
| Missing image URLs | Images lazy-loaded differently or hidden by layout variation | Rerun after the page fully loads and inspect the image area. |
| Rating mismatch | Rating text changed by locale or module placement | Compare against the browser and update the extraction script if needed. |
| Duplicate rows | Same URL supplied twice or a rerun appended to an existing file | Deduplicate by asin and web_page_url. |
Alternatives
Amazon scraper API, PA-API, or local desktop app?
UScraper is a good fit when you need a supervised no-code workflow, visible browser QA, CSV output, and local control over the input list and export file.
An Amazon scraper API can make sense for JSON responses, proxy handling, scheduling, and cloud throughput. Hosted actors and scraper APIs reduce infrastructure work, but usually add usage billing and third-party processing. The official Amazon Product Advertising API is a different route for approved developers who need sanctioned metadata access, credentials, quotas, and API-specific fields.
| Option | Good fit | Trade-off |
|---|---|---|
| UScraper template | Reviewed ASIN batches, local CSV export, no-code editing | Best for supervised runs, not unattended high-volume crawling. |
| Scraper API or cloud actor | Managed infrastructure, JSON endpoints, scheduling | Usage billing and third-party processing are part of the workflow. |
| Product Advertising API | Approved API use cases and official metadata workflows | Requires eligibility, credentials, implementation work, and API limits. |
FAQ
Amazon Mexico product scraper FAQ
Amazon Mexico product pages may be publicly visible, but automated collection can still be limited by Amazon terms, robots directives, anti-abuse controls, marketplace policies, intellectual property rights, privacy law, and local regulations. Review source rules, use modest batches, do not bypass CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon Mexico product detail scraper
When you are ready to run the tutorial, open Amazon Mexico Product Detail Scraper and import the JSON into UScraper. For neighboring workflows, browse the UScraper template library or the UScraper blog for more scraping tutorials.