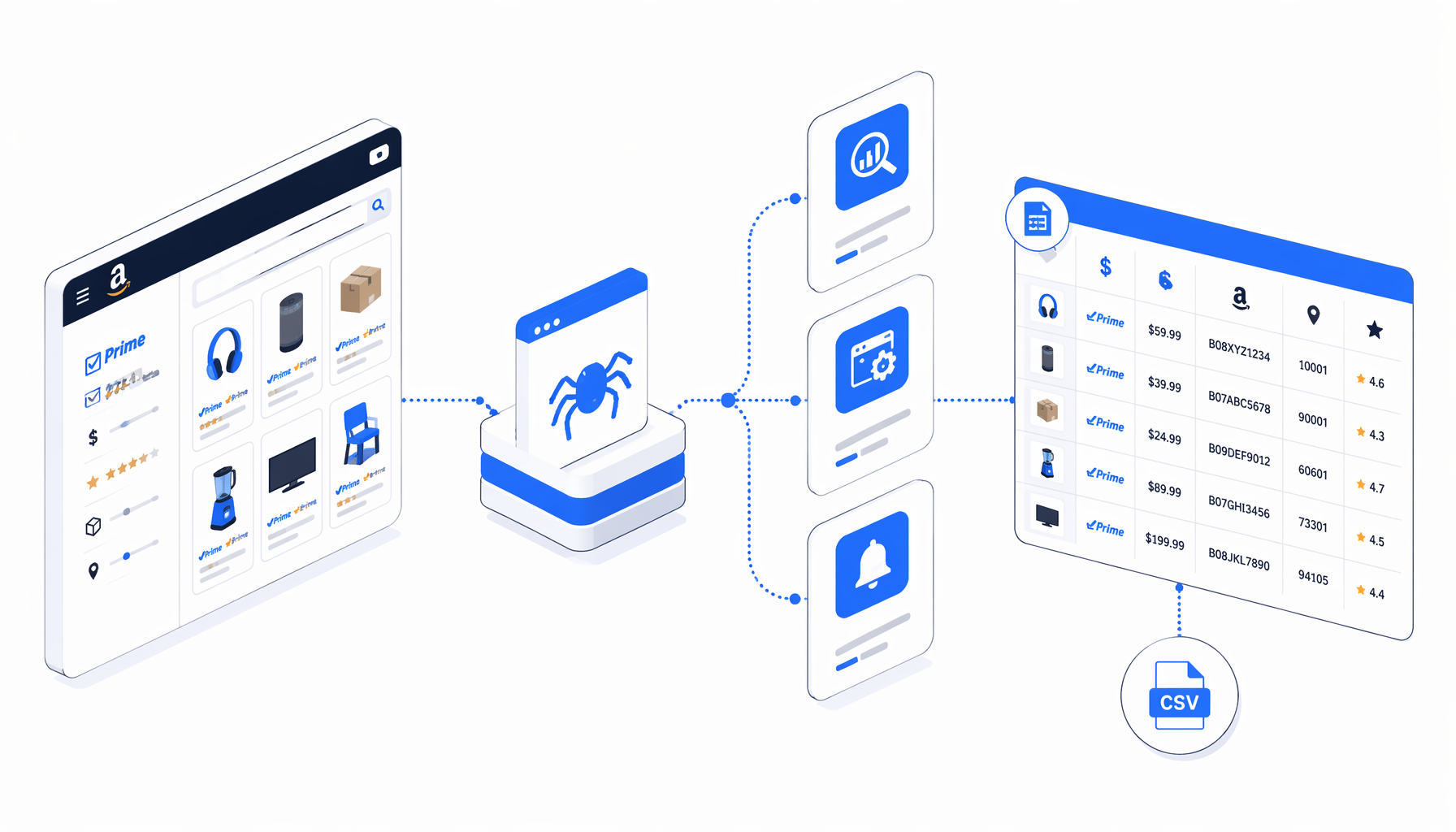
An Amazon Prime scraper is most useful when the question is narrow: which Prime-filtered products show up for this keyword, delivery context, and run date? The Amazon Prime Scraper template turns that browser workflow into a local desktop app export with titles, prices, ASINs, product URLs, ZIP context, ratings, and timestamps in CSV.
Use-case frame
Why Prime-filtered Amazon data needs context
Prime-filtered search results are not a static product catalog. Results can shift by keyword wording, delivery ZIP, session state, sponsored modules, availability, price display, page layout, and the moment the run happens. That is why copying visible listings into a spreadsheet creates weak evidence: the numbers may be right, but the context often gets lost.
For many teams, the goal is not to scrape Amazon at maximum scale. The goal is to build a repeatable table from the pages a human is already reviewing. A useful amazon prime product scraper should preserve the source URL, ZIP context, ASIN, price, rating signal, and run time so the row can be checked against the browser.
A Prime listing without keyword, location, and timestamp context is not a research row. It is a loose note from a moving marketplace.
Personas
Who uses an Amazon Prime scraper?
| Persona | Pain | Useful export outcome |
|---|---|---|
| Ecommerce researchers | Browser tabs make it hard to compare which Prime products appear for a keyword. | Export titles, ASINs, prices, product URLs, stars, rating counts, ZIP code, and collection time for spreadsheet screening. |
| SEO teams | Amazon result pages reveal product language, category patterns, and review depth that can inform briefs. | Collect keyword-specific titles, prices, ratings, and URLs for content research without pasting rows by hand. |
| Agencies | Client reports need repeatable evidence, not screenshots scattered across a folder. | Run the same Prime-filtered search and attach a validated CSV to the analysis. |
| Newsrooms and analysts | Marketplace claims need scoped checks with clear sampling assumptions. | Capture what was visible for a keyword and location at a specific run time, then verify findings manually before publication. |
| Monitoring teams | Price and review signals change, but manual checks are slow and inconsistent. | Re-run a saved search context and compare ASIN-level changes across CSV snapshots. |
The workflow is intentionally scoped. It is not a replacement for Amazon Product Advertising API, a managed marketplace data feed, or a production inventory system. It fits supervised, CSV-first research where a human owns the source list, reviews the first page, and keeps the run notes with the output.
Workflow
How the template delivers structured export
The bundled workflow opens an Amazon.com search URL with the Prime filter already active, waits for search-result cards with ASINs, exports visible fields, checks whether Amazon exposes an enabled Next button, clicks it, waits for the next page, sleeps briefly, and loops until no further page is available.
{
"project": "Amazon Prime Scraper",
"start_url": "https://www.amazon.com/s?k=hair%2Bcare%2B&rh=p_85%3A2470955011&page=1",
"rowSelector": "div[data-component-type=\"s-search-result\"][data-asin]:not([data-asin=\"\"])",
"fileName": "amazon-prime-scraper.csv",
"fileMode": "append",
"pagination": "a.s-pagination-next:not(.s-pagination-disabled)",
"columns": [
"listing_url",
"zip_code",
"title",
"price",
"asin",
"product_url",
"keyword",
"stars",
"rating_count",
"current_time"
]
}
amazon-prime-scraper.csvColumn
listing_url
The Amazon search result page that produced the row.
Column
zip_code
Detected delivery ZIP when Amazon exposes it in the browser session.
Column
title
Visible product title from the search listing card.
Column
price
Visible price when Amazon renders one for the listing and session.
Column
asin
ASIN from the result card or product URL fallback.
Column
product_url
Full product URL built from the listing link.
Column
keyword
Search keyword parsed from the current Amazon URL.
Column
stars
Rating text such as 4.5 out of 5 stars.
Column
rating_count
Visible rating or review count from the listing card.
Column
current_time
Local timestamp when the row was exported.
That export shape is the difference between scraping and usable research. The ASIN helps deduplicate. The product URL supports QA. The listing URL and keyword explain the search context. The ZIP code and timestamp make later comparisons honest.
Scenarios
Concrete Amazon Prime scraper use cases
Use the scraper to compare Prime-filtered products for one keyword at a time. Sort by price, rating count, star rating, ASIN, and product URL to identify crowded ranges, weak review coverage, and listings worth deeper product-page review.
Assortment gap checks
A seller or category researcher can run a Prime-filtered keyword, dedupe by ASIN, and group rows by price band or rating depth. The output will not explain why Amazon ranked those products, but it gives a clean shortlist for manual review.
Product SEO briefs
SEO teams can use title text, rating counts, and visible pricing to understand what Amazon exposes for a category phrase. The CSV is useful input for briefs, but it should not be treated as a complete product corpus.
Recurring marketplace snapshots
Monitoring teams can save the same search URL, keep the same ZIP context, and append or version CSVs by date. This makes it easier to separate true marketplace movement from collection mistakes.
Newsroom sampling
Reporters can use the export to structure a sample before manual verification. The key is restraint: state the keyword, ZIP, date, and visible result scope, then verify critical rows directly in the browser.
Runbook
A repeatable problem-solution workflow
Define the sample
Pick the keyword, delivery context, expected page range, and reason for collection before opening the template.
Prepare the Prime-filtered URL
Search Amazon, apply the Prime filter, set the delivery ZIP context in the browser profile, and copy the final search URL.
Import and configure
Download the Amazon Prime Scraper template, replace the Navigate URL, and confirm the local CSV save folder.
Run one page first
Export a single page and compare several rows against the browser for title, price, ASIN, product URL, ZIP code, stars, and rating count.
Continue only after QA
Let pagination run after the first page is clean. Stop if Amazon shows verification, repeats the same page, drops the ZIP context, or changes the result layout.
| Decision | Use the CSV when... | Escalate to another route when... |
|---|---|---|
| Research batch | The team needs a reviewable spreadsheet from visible Prime-filtered listings. | The job needs guaranteed coverage, remote scheduling, or very high volume. |
| Application data | The CSV informs a one-off analysis or human workflow. | The data feeds a product, customer dashboard, or commercial redistribution path. |
| Streaming data | The project is not about Prime Video. | The target is title availability, VOD charts, or playback-related metadata. |
For approved product applications, evaluate the Amazon Product Advertising API or another licensed provider. For collection policy review, start with Amazon robots.txt and Amazon Conditions of Use, then get legal review for your specific use case.
FAQ
Amazon Prime scraper use-case FAQ
Use an Amazon Prime scraper when researchers, SEO teams, agencies, or ecommerce analysts need a controlled CSV from Prime-filtered Amazon shopping search listings. It is best for supervised research batches, not for bypassing Amazon access controls or building a production marketplace feed.
Next step
Start with one Prime-filtered search
Pick one keyword, set the delivery ZIP context, and run one page before widening the batch. If the workflow fits your use case, open the Amazon Prime Scraper template, then browse the UScraper template library or return to the UScraper blog for adjacent Amazon scraper tutorials and comparisons.