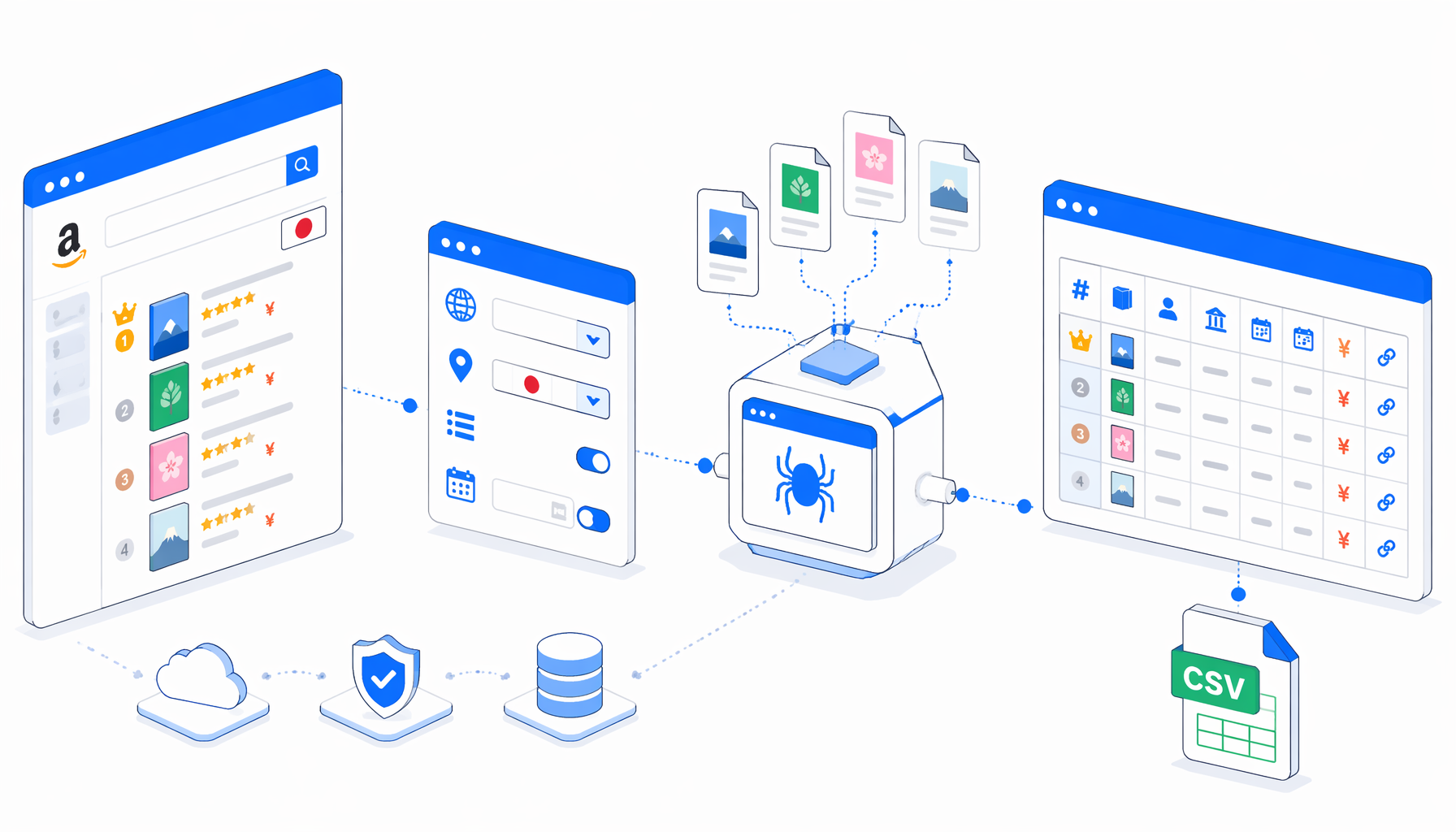
This tutorial shows how to scrape Kindle rankings from Amazon.co.jp Kindle Best Sellers pages into CSV with the Amazon Kindle Rankings Scraper Japan template for UScraper. You will import the workflow, review the ranking URLs, set the export path, validate the CSV, and handle common empty-field issues.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, Kindle ranking URLs you are allowed to process, and a folder where CSV exports can be written. Start with the four bundled Amazon.co.jp URLs before adding more categories.
This guide is for supervised research exports from pages you can inspect in a browser. It is not a bypass guide for CAPTCHA, login-only data, account pages, checkout flows, or private seller dashboards.
Technical access is not permission. If the data will support commercial decisions, redistribution, or a production product, document the basis for collection and get legal review.
Workflow anatomy
What the Amazon Kindle rankings scraper does
The template follows a compact graph: Navigate -> Wait for Page Load -> Wait for Element -> Inject JavaScript -> Structured Export -> Loop Continue. Navigate owns the URL list. The waits make sure ranking cards are visible. JavaScript cleans text, records the category, marks ready rows, and attempts detail-page enrichment for language, publisher, and release date. Structured Export writes the columns. Loop Continue advances to the next ranking URL.
Amazon's Kindle Best Sellers pages expose ranked category lists in a browser. Amazon Product Advertising API documentation is a different path: if you already qualify for PAAPI, BrowseNodeInfo and SalesRank resources may fit governed API workflows. This article focuses on browser export to CSV, where the critical checks are simple: ranking cards rendered, ready rows exist, headers are enabled, and append mode is on.
Output shape
Amazon Kindle rankings CSV fields
The export is one row per captured Kindle ranking card. Rank, title, author, price, and product URL come from the ranking page when visible. Language, publisher, and release date come from the detail-page enrichment step when reachable.
| Column | Meaning | Validation check |
|---|---|---|
category | Page heading, such as a Kindle Best Sellers category | Compare it with the browser heading. |
category_url | Exact ranking URL loaded by UScraper | Keep this for reruns and audit notes. |
ranking | Visible list position, such as #1 | Confirm card order in the browser. |
title | Kindle book title from card text or image alt text | Open the product URL and compare the title. |
author | Author text visible on the ranking card | Expect blanks when Amazon hides it. |
language | Detail-page language field, when available | Treat as optional because enrichment can fail. |
publisher | Detail-page publisher field | Spot-check against product details. |
release_date | Publication or release date | Format can vary by locale. |
price | Visible Kindle price | Recheck if region or sign-in state changed. |
product_url | Absolute Amazon.co.jp product URL | This is the key field for dedupe and manual QA. |
Runbook
How to scrape Amazon Kindle rankings to CSV
Import the template
Open Amazon Kindle Rankings Scraper Japan, download the JSON, and import it into UScraper.
Review ranking URLs
Open Navigate and confirm the Amazon.co.jp Kindle Best Sellers URLs. Keep the bundled URLs for a first test, then add category URLs only after the dry run passes.
Confirm waits
Keep the page-load wait and the ranking-card visibility check. If Amazon shows a prompt, handle it in the browser before trusting the export.
Set the export folder
In Structured Export, confirm amazon_jp_kindle_rankings_scraper.csv, headers, append mode, and a local save folder for this project.
Run one page first
Run a single ranking URL, inspect the CSV, and compare three rows against the browser. Then restore the full URL loop.
If the first page works, run the bundled loop. Add new categories deliberately rather than pointing the workflow at every Amazon category at once. Ranking pages are easier to validate when the input list is small and named.
Validation
Validate Kindle ranking rows before analysis
Open the CSV after the first run and sort by category_url, then by ranking. One ranking card should become one row. Use product_url as the audit trail.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Ranking cards did not render or the selector no longer matches | Open the page in the browser, handle prompts, and refresh the row selector if needed. |
| Rows have rank but no metadata | Detail-page enrichment was blocked or timed out | Keep the row, then rerun a smaller batch or treat enrichment fields as optional. |
| Price looks inconsistent | Amazon changed region, language, availability, or sign-in state | Preserve the same browser context and rerun a single URL for comparison. |
| Duplicate books appear | The same category page was added twice or page 1/page 2 overlap | Dedupe by category_url, ranking, and product_url. |
Alternatives
UScraper vs PAAPI, cloud actors, and scraper APIs
Searches such as amazon best sellers scraper api, amazon paapi sales rank, and amazon kindle scraper alternative often mix different jobs. Pick the route based on rights, volume, and data custody.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Supervised Kindle category snapshots exported to CSV | You validate selectors and keep batches modest. |
| Amazon Product Advertising API | Approved affiliate or API workflows with governed access | Eligibility, resource coverage, and API terms control what you can request. |
| Hosted scraper API or actor | Managed runtime and scheduling | Data passes through vendor infrastructure and pricing is usually usage-based. |
UScraper fits the analyst workflow: import a template, watch the browser, export a local CSV, and inspect the result before sharing. APIs and hosted actors can be better for programmatic scale or contracted data access.
FAQ
Amazon Kindle rankings scraping FAQ
Amazon.co.jp Kindle ranking pages may be publicly visible, but automated collection can still be limited by Amazon Conditions of Use, robots rules, marketplace policies, copyright, privacy law, and local regulations. Keep runs modest, do not bypass CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon Kindle rankings scraper Japan template
When you are ready to run the tutorial, download the JSON from Amazon Kindle Rankings Scraper Japan and keep this article open for QA. For adjacent workflows, browse the UScraper template library or the UScraper blog for more CSV export tutorials.