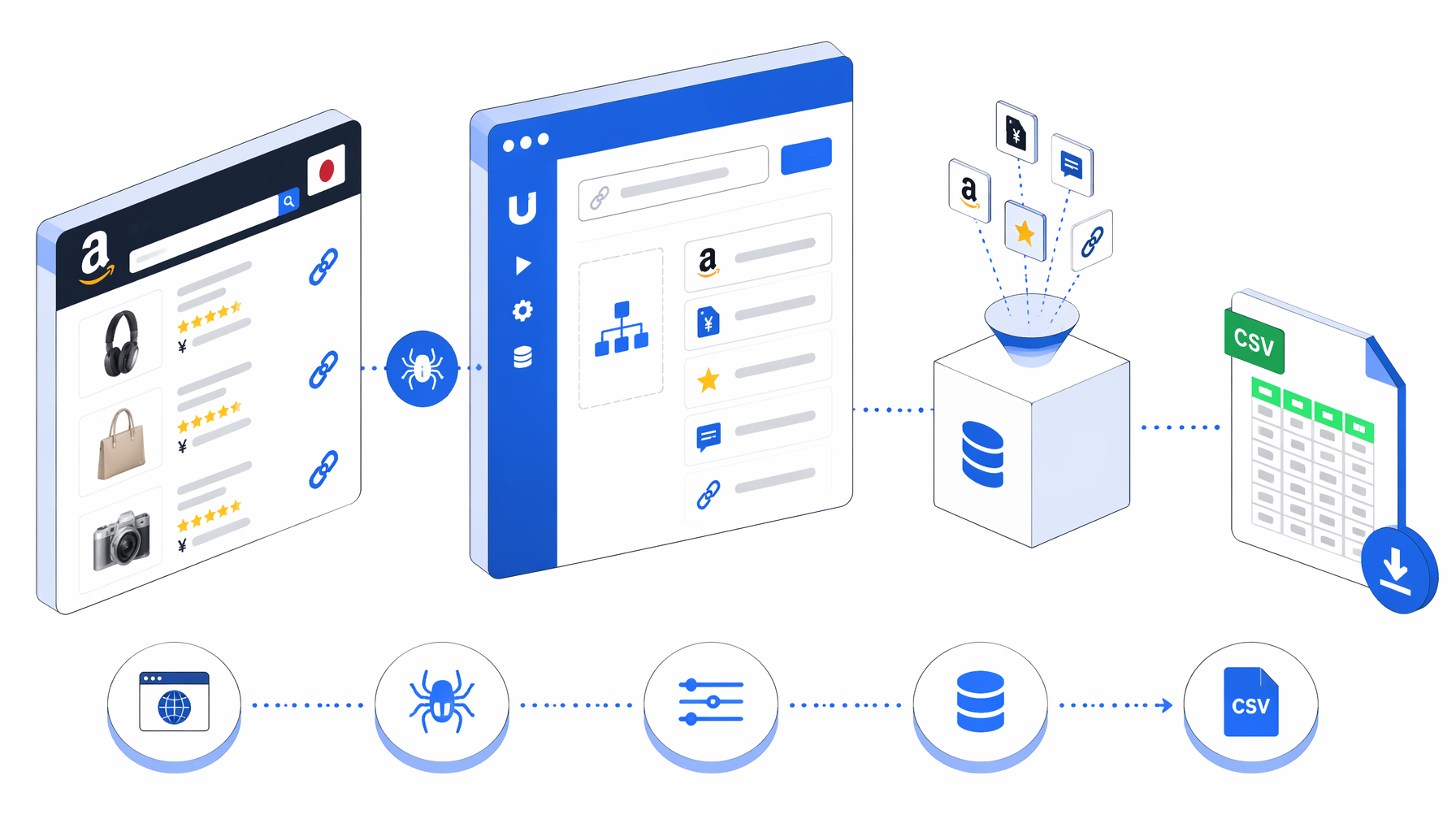
This tutorial shows how to scrape Amazon Japan product detail URLs into CSV with the Amazon Japan URLs Scraper for UScraper. You will import the workflow, replace the sample ASIN URLs, confirm the export path, run the loop, and validate the resulting product rows.
Before you start
Prerequisites and Amazon Japan policy checks
You need UScraper installed as a local desktop app, a small set of Amazon.co.jp product URLs you are allowed to process, and a folder where CSV files can be written. Start with five to ten URLs, not hundreds. Amazon pages can vary by region, language, stock state, delivery context, session, and anti-abuse checks.
This guide is for visible product detail pages such as https://www.amazon.co.jp/dp/B07HRF5NXP. It is not for account pages, seller dashboards, checkout flows, private data, login-only pages, or CAPTCHA bypassing. Review Amazon.co.jp's Conditions of Use, check Amazon.co.jp robots directives, and prefer official routes such as the Product Advertising API Japan locale when you need contractual product data access.
Technical access is not the same as permission. Keep batches modest, do not evade access controls, document why the URLs were collected, and get legal review before commercial redistribution.
Workflow anatomy
What the Amazon Japan URLs scraper does
The bundled JSON export is the source of truth for the workflow. In plain English, it runs this sequence:
Navigate with ASIN URLs -> Wait for Page Load -> Wait for body
-> Sleep -> Structured Export -> Loop Continue
The Navigate block holds multiple Amazon.co.jp product URLs. The wait blocks give each detail page time to settle. Structured Export writes one row from the page body, and Loop Continue advances to the next configured URL. Because export mode is append, all products land in the same CSV.
| Workflow part | Important setting | Why it matters |
|---|---|---|
| Navigate | urls contains Amazon.co.jp /dp/ pages | Use this for reviewed ASIN lists, not keyword discovery. |
| Wait for Element | selector: body | Keeps the run simple across varied product templates. |
| Sleep | duration: 2 | Gives dynamic price and rating modules a short buffer. |
| Structured Export | fileName: amazon-japan-urls-scraper.csv | Creates the spreadsheet-ready output. |
| Loop Continue | End of the loop body | Moves from one product URL to the next. |
The template does not include a sample CSV in the bundle, so use the JSON definition and the first test run as your authoritative preview. The stock export columns are intentionally narrow: product identity, trust signals, visible price, source URL, and collection time.
| CSV column | What it captures | Validation check |
|---|---|---|
ASIN | ASIN parsed from /dp/, /gp/product/, hidden inputs, or query fallback | Confirm it matches the product URL. |
Title | #productTitle, title fallback, or page metadata | Compare against the visible product title. |
Star_Rating | Average star text when Amazon renders it | Expect blanks on unavailable or changed layouts. |
Number_of_Reviews | Review-count text reduced to the numeric portion | Compare against the visible review link. |
Price | Visible yen price from common price selectors | Check stock state, variation selection, and regional messages. |
Detail_Page_URL | Current browser URL | Use it for dedupe and audit trails. |
Current_Time | Local scrape timestamp | Useful for price and rating snapshots. |
Runbook
How to scrape Amazon Japan product data by URL
Import the template
Open Amazon Japan URLs Scraper, download the workflow JSON, and import it into UScraper.
Replace the sample URLs
Open Navigate and replace the bundled sample pages with your approved Amazon.co.jp product URLs. Use canonical /dp/{ASIN} links where possible.
Confirm waits
Keep the page-load wait, body wait, and short sleep in place. If price or rating modules load slowly in your session, increase the sleep before Structured Export.
Set the CSV destination
In Structured Export, confirm amazon-japan-urls-scraper.csv, headers, append mode, and the save folder for this project or client.
Run one URL first
Run a single ASIN, inspect the browser and CSV together, then reconnect the full multi-URL loop only after the first row is clean.
After the first clean run, clear the test CSV or rename the output file with a date. Append mode is useful for loops, but it will also append repeated test rows if you rerun into the same file.
Validation
Validate the Amazon Japan CSV export
Open the CSV beside the browser and check one product from the start, middle, and end of the run. A clean Amazon Japan ASIN scraper workflow should create one row per input URL, preserve the ASIN, and make blank cells explainable.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty title | Page did not reach a product-detail state | Open the URL manually, handle prompts, and rerun one ASIN. |
| Blank price | Product unavailable, variation required, regional message, or delayed price module | Check the same URL in the browser and extend the wait if the price appears late. |
| Missing rating | Rating module is absent or selector changed | Treat unrated products as valid blanks, but update the selector if the browser shows a rating. |
| CAPTCHA text exported | Amazon interrupted the page | Stop the run. Do not automate bypassing; reduce volume and review permission. |
| Duplicate rows | Same URL supplied twice or a test run was appended | Dedupe by ASIN and Detail_Page_URL, then clear the CSV before reruns. |
Alternatives
UScraper vs Octoparse, Apify, Bright Data, and APIs
If you searched for "amazon japan url scraper" or "octoparse amazon japan alternative", you are usually choosing between four paths: a local no-code workflow, a no-code hosted scraper, a cloud actor, or a commercial scraping API.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV export from reviewed ASIN URLs in a local desktop app | You manage pacing, validation, and selector maintenance. |
| Octoparse Amazon Japan templates | Teams already using Octoparse for no-code scraping projects | Workflow custody and pricing depend on that platform. |
| Apify Amazon actors | Cloud runs, API integration, scheduled jobs, and larger automation pipelines | More infrastructure surface and usage-based operations to manage. |
| Bright Data or Oxylabs APIs | Teams needing managed Amazon extraction infrastructure | Better for formal data operations, but usually heavier than a quick CSV tutorial. |
| Amazon Product Advertising API | Approved affiliate and catalog use cases | Requires eligibility and API-specific usage rules, and may not expose every visible page detail. |
UScraper is the practical choice when the input is already a clean ASIN URL list and the output needs to be a local CSV that a researcher can inspect. If you need continuous production ingestion, official or managed API routes may be more durable.
Common issues
Common Amazon Japan scraping issues
Use canonical product-detail URLs such as https://www.amazon.co.jp/dp/B07HRF5NXP. If your link redirects through search, tracking, or a storefront path, open it in the browser and copy the final /dp/ URL before running the batch.
FAQ
Amazon Japan URL scraper FAQ
Amazon.co.jp product pages may be visible in a browser, but automated collection can still be limited by Amazon terms, robots directives, anti-abuse systems, intellectual property rights, privacy law, and local regulations. Use reviewed URLs, avoid bypassing CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon Japan URLs scraper template
When you are ready to run the workflow, download the JSON from Amazon Japan URLs Scraper and keep this tutorial open for validation. For neighboring workflows, browse the UScraper template library or the UScraper blog for more CSV export tutorials.