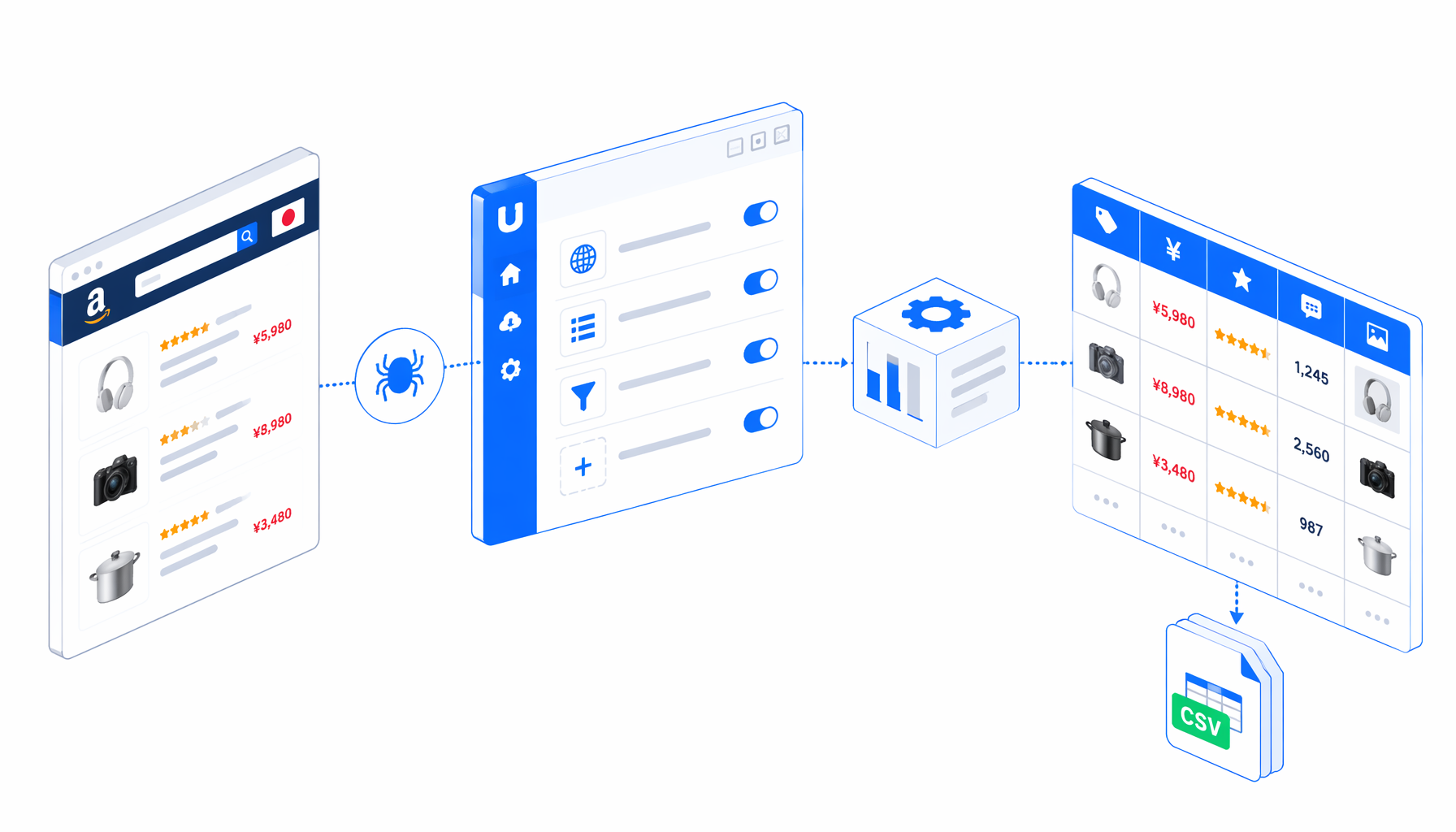
This tutorial shows how to scrape Amazon Japan product listings into CSV with the Amazon Japan Product Listings Scraper for UScraper. You will import the workflow, edit the Amazon.co.jp search URL, set the export path, run one keyword, and validate ASIN, price, review, sponsored, and image fields before scaling.
Before you start
Prerequisites and Amazon Japan policy checks
You need UScraper installed as a local desktop app, one Amazon.co.jp search URL you are allowed to process, and a folder where the CSV can be saved. Start with a narrow keyword such as a brand, model, category phrase, or the sample https://www.amazon.co.jp/s?k=kindle&language=en_US. Do not start with a long keyword list.
This guide covers supervised collection from visible search result pages. It does not cover account pages, seller dashboards, checkout flows, login-only content, CAPTCHA bypassing, or resale of scraped data. Before automation, review the current Amazon.co.jp conditions of use and Amazon.co.jp robots.txt. If your use case needs approved product data access, also compare this workflow with Amazon's Product Advertising API Japan locale reference and SearchItems documentation.
Technical access is not the same thing as permission. Keep the browser visible, avoid access-control bypassing, document the business purpose, and use official or licensed routes when the output will feed a production system.
Workflow anatomy
What the Amazon Japan product listings scraper does
The bundled JSON is the workflow contract. It starts with Navigate, waits for the page to load, sleeps briefly, waits for Amazon search-result cards, and then runs Structured Export against every non-empty result card. After export, an Element Exists block checks for a live Next link. If Next exists, UScraper clicks it, waits again, and returns to the same Structured Export block. If Next is disabled or removed, the workflow ends.
The template generates product and review URLs from ASIN because marketplace listing links can include inconsistent tracking parameters. That keeps the CSV easier to dedupe and join with later product-detail work.
| CSV column group | Fields | How to validate |
|---|---|---|
| Search context | site, delivery_destination, keyword, page_number | Confirm the keyword and delivery location match the browser session. |
| Product identity | product_name, product_url, asin, image_url | Open two generated product URLs and verify the ASINs. |
| Marketplace signals | sponsored, ranking, review_count, review_url | Compare visible ad labels and review counts on the first page. |
| Pricing | price, previous_price | Expect blanks when Amazon hides or delays offer modules. |
Runbook
How to scrape Amazon Japan search results to CSV
Import the template
Open Amazon Japan Product Listings Scraper, download the JSON, and import it into UScraper.
Edit the search URL
In Navigate, replace k=kindle with your approved keyword. Keep language, marketplace, and delivery-location context aligned with the report you need.
Confirm the export folder
Structured Export writes amazon_jp_product_listings_scraper.csv with headers enabled and file mode set to append. Change the save folder for each project or run date.
Run one page
Let the page load, handle any visible location or consent prompts manually, and confirm that product cards appear before the Structured Export block fires.
Review, then continue
Open the CSV, compare several rows against the browser, then let the Next-button loop continue through reachable result pages.
After the first export, sort by page_number, asin, and sponsored. One visible result card should create one row. If the same ASIN appears twice, confirm whether Amazon showed the item in both organic and sponsored placements before deduping it.
Quality control
Validate the export before using the data
Amazon.co.jp result pages are dynamic, so validation is part of the scraping workflow. Keep the browser tab open beside the CSV and inspect rows from the first page, a middle page, and the final page reached by the pagination loop.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Product cards did not render, a prompt blocked the page, or the row selector no longer matches | Handle prompts, wait for visible cards, then rerun one keyword. |
Blank price | Offer hidden by location, unavailable item, delayed module, or page variant | Check the visible listing and treat price as optional unless your session shows it. |
Wrong delivery_destination | Amazon used a default location or prompted for postal code | Set the location in the browser profile before running the keyword. |
| Missing review count | The card has no reviews, the review link is hidden, or locale text changed | Compare the card manually and adjust the selector if the pattern changed. |
| Pagination stops early | Amazon removed or disabled the Next link for that keyword/session | Keep the last page reached and record the run context in your audit notes. |
Alternatives
UScraper vs APIs, hosted scrapers, and code tutorials
UScraper fits a specific job: a supervised local CSV export where an analyst wants to see the Amazon.co.jp page, adjust a no-code workflow, and keep the output on disk. Other approaches can be better when you need contracts, scale, or production ingestion.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Keyword snapshots, ASIN discovery, sponsored-result review, spreadsheet QA | You maintain selectors when Amazon changes result-card markup. |
| Amazon Product Advertising API | Approved affiliate or product-data workflows with documented API rules | Requires eligibility, credentials, request signing, and API-specific output limits. |
| Hosted scraper or API provider | Cloud scheduling, managed proxies, large crawls, or vendor-maintained parsing | Queries and results pass through the provider, and pricing is usually usage-based. |
| Custom Python scraper | Developer-controlled experiments and fully custom parsing | You own anti-bot handling, selectors, retries, storage, and compliance review. |
If you are comparing best Amazon Japan scraper options, look at custody first. Octoparse-style templates are useful for no-code cloud runs, Apify-style actors are useful for managed cloud automation, and Bright Data or Oxylabs-style APIs are useful when the requirement is provider infrastructure. The UScraper angle is simpler: import a template, watch the page, export CSV locally, and review before sharing.
FAQ
Frequently asked questions
Amazon.co.jp search result pages may be visible in a browser, but automated collection can still be restricted by Amazon terms, robots directives, anti-abuse systems, intellectual property rights, privacy law, and local regulations. Review the source rules, avoid CAPTCHA or access-control bypassing, keep runs modest, and get legal review before commercial reuse.
Next step
Download the workflow and run a dry test
Use the Amazon Japan Product Listings Scraper as the download path, then come back to this runbook for validation and troubleshooting. For adjacent marketplace workflows, browse the UScraper template library or the UScraper blog for other tutorials that pair listing exports with product-detail, review, and URL-list workflows.