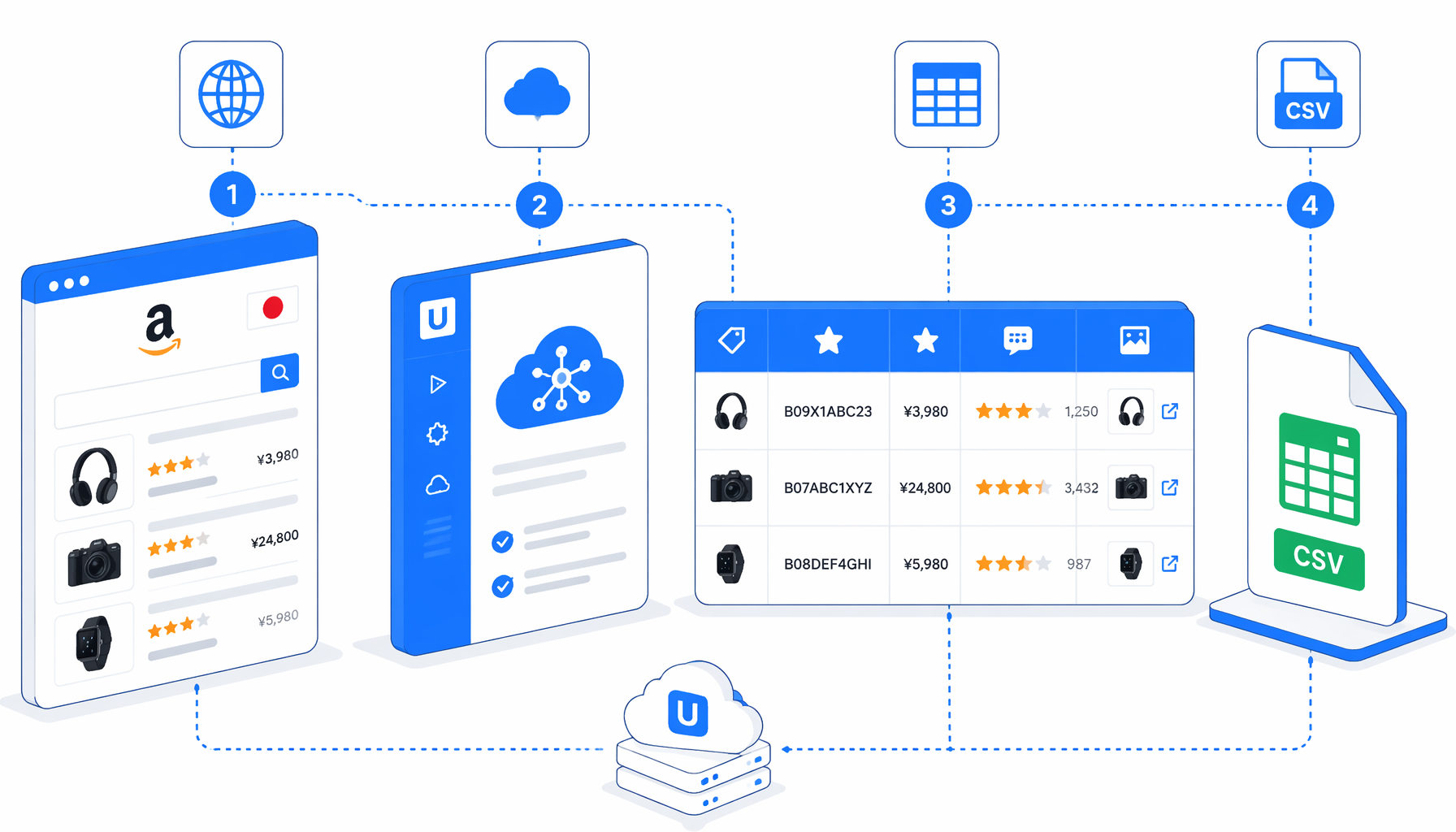
This tutorial shows how to scrape Amazon Japan product listings from Amazon.co.jp keyword search results into CSV with the Amazon Japan Product Listings Scraper for UScraper. You will import the template, change the keyword, set the export path, validate one page, and troubleshoot common Amazon search-page issues.
Before you start
Prerequisites, scope, and Amazon policy checks
You need UScraper installed as a local desktop app, an approved keyword, and a folder for CSV files. Start with one low-risk keyword such as kindle or an internal brand term. Do not begin with a long keyword list; Amazon.co.jp can show region prompts, localized availability, CAPTCHA checks, sponsored modules, or alternate card layouts.
This guide covers public Amazon.co.jp search result pages, not account pages, Seller Central, cart flows, checkout, login-only data, or bypassing anti-abuse systems. Before automation, review the current Amazon.co.jp Conditions of Use and Amazon.co.jp robots.txt. For approved affiliate or production use, compare this browser workflow with the official Product Advertising API Japan locale documentation and SearchItems documentation.
Technical access is not permission. Keep runs modest, avoid access-control bypassing, document your purpose, and use licensed data routes when needed.
Workflow anatomy
What the Amazon Japan product listings scraper exports
The bundled JSON sets a fixed browser viewport, navigates to https://www.amazon.co.jp/s?k=kindle&page=1&language=en_US, waits for search result cards, and runs Structured Export against div.s-main-slot div[data-component-type="s-search-result"][data-asin]:not([data-asin=""]). After export, a condition block checks for a.s-pagination-next:not(.s-pagination-disabled). If the Next button exists, the workflow clicks it, waits again, and loops back into Structured Export. If not, the run ends.
The JSON export is the authoritative workflow definition: one product-card row per listing, with context fields that make the CSV easier to audit after pagination.
| CSV field | What it captures | Validation check |
|---|---|---|
site, deliver_to, keyword, page_number | Browser context and search state | Confirm the keyword and page number match the URL you ran. |
product_name, product_url, asin | Product identity fields | Open two product URLs and confirm ASINs match the listing cards. |
sponsored, ranking, review_count | Ad and trust signals visible on the card | Expect blanks when Amazon does not show those modules. |
price, past_price | Current and crossed-out price text | Validate against the same delivery location and language state. |
review_url, image_url | Follow-up links for QA and enrichment | Use these for manual spot checks, not as proof of rights. |
There is no bundled CSV sample, so your first run is part of setup. The expected output file is amazon-jp-product-listings-cloud-only-scraper.csv with headers and append mode enabled.
Runbook
How to scrape Amazon Japan product listings to CSV
Import the template
Open Amazon Japan Product Listings Scraper, download the JSON, and import it into UScraper.
Change the keyword
In the Navigate block, edit the k= parameter. Keep language=en_US if you want English interface labels, or change language only after testing selectors.
Set the export folder
In Structured Export, confirm the CSV name, headers, append mode, and a project-specific save location. Avoid reusing one CSV across unrelated keywords.
Run one page first
Let the page load, resolve address or verification prompts manually, and inspect the first CSV rows before allowing the pagination loop to continue.
Scale with pauses
Increase volume only after the row shape is correct. Keep the browser visible and stop when Amazon shows CAPTCHA, unexpected prompts, or abnormal empty pages.
After the dry run, sort by page_number, then by asin. A normal run appends pages until Amazon disables the Next button. If rows repeat, clear or rename the CSV before rerunning.
Validation
Validate Amazon product data Japan exports
Amazon product data is volatile. Prices, availability, delivery location, sponsored labels, ratings, and review counts can change between runs. Keep the browser beside the CSV and verify rows from the first, middle, and last pages.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | CAPTCHA, address prompt, slow render, or selector drift | Resolve prompts, extend waits, and rerun a single page. |
Blank price cells | Price hidden for the session, unavailable item, or alternate card layout | Check the listing in the same browser state and treat price as optional. |
| Wrong keyword in rows | The Navigate URL was changed but an old page stayed loaded | Reload from page one and clear the previous CSV before retesting. |
| Missing sponsored marker | Amazon changed label markup or language | Inspect the visible card text and update the sponsored column logic. |
| Duplicate ASINs | Sponsored and organic cards repeat, or append mode reused an old file | Dedupe by keyword, page number, ASIN, and product URL. |
Alternatives
Octoparse Amazon Japan alternative, APIs, and hosted tools
If you search for amazon co jp scraper tutorial or octoparse amazon japan alternative, you will see several paths. Octoparse provides Amazon Japan templates, including cloud-oriented listing workflows. Apify, Bright Data, Oxylabs, ScrapingBee, SerpApi, Rainforest API, ZenRows, and Scrapfly focus on hosted APIs, managed proxies, or code-first extraction.
UScraper fits a supervised local CSV workflow where an analyst wants browser QA, editable blocks, and an on-disk export. Hosted APIs are better for scheduling, infrastructure, scale, or vendor-managed parsing. Product Advertising API is cleaner when your use case fits Amazon's approved Associate-program data model.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Research exports, QA, keyword snapshots, analyst-owned CSV files | You maintain selectors when Amazon changes markup. |
| Octoparse-style cloud template | Managed cloud runs and template marketplace familiarity | Data custody, usage limits, and cloud pricing depend on the vendor. |
| Amazon Japan scraping API provider | Production ingestion, proxies, SLAs, or larger job queues | Usually requires keys, usage fees, and vendor-specific terms. |
| Product Advertising API | Approved affiliate-style item search and product metadata | Requires program eligibility and may not match every research workflow. |
For neighboring workflows, browse the UScraper template library or start from the UScraper blog.
FAQ
Amazon Japan scraper FAQ
Amazon.co.jp pages may be visible in a browser, but automated collection can still be limited by Amazon terms, robots directives, access controls, intellectual property rights, privacy law, and local regulations. Review the current Conditions of Use and robots.txt, keep runs modest, and do not bypass controls.
Next step
Download the Amazon Japan product listings scraper
When you are ready to run the workflow, download the JSON from Amazon Japan Product Listings Scraper and keep this tutorial open for validation. Start with one keyword, confirm the CSV shape, then decide whether the local desktop workflow, an Amazon Japan scraping API, or Product Advertising API is the right long-term path.