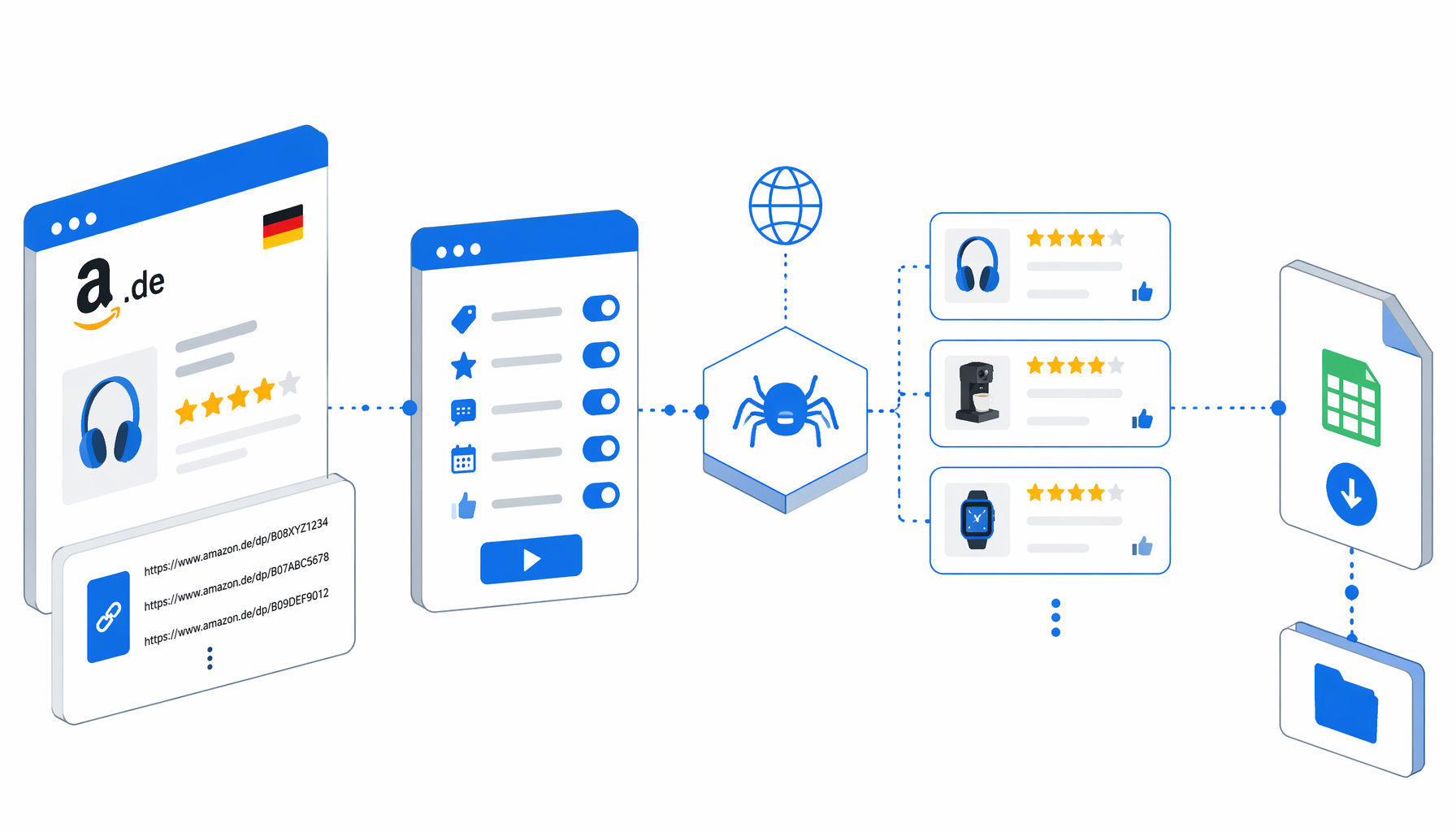
This tutorial shows how to scrape Amazon.de reviews from product detail URLs into CSV with the Amazon Germany Review Scraper with URLs for UScraper. You will import the workflow, replace the sample Amazon.de URLs, set the export path, run a small validation batch, and handle the common cases that make Amazon review pages return no rows.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, a short list of Amazon.de product detail URLs you are allowed to process, and a folder where CSV exports can be written. Start with two or three product URLs, not a full catalog. Amazon pages vary by locale, account state, stock status, review availability, and anti-bot checks, so your first run is a QA pass.
This guide is for supervised review exports from pages you can inspect in a normal browser. It is not a guide to bypassing CAPTCHA, sign-in walls, payment flows, account pages, or access controls. Before automation, review Amazon.de customer review guidance and the current Amazon.de robots.txt, then decide whether your use case needs legal review or an approved data provider.
Technical access is not permission. Keep batches modest, document the purpose of collection, and stop when Amazon asks for manual validation.
Workflow anatomy
What the Amazon Germany review scraper with URLs does
The template is built for URL-based review collection. The Navigate block stores your product detail URLs. JavaScript derives the ASIN from each URL or page, saves it locally in the browser session, and moves to an Amazon.de /product-reviews/ URL with reviewerType=all_reviews. If Amazon shows a "Weiter shoppen" interstitial, the workflow clicks through when the expected control exists. If direct review navigation does not expose rows, it falls back to the product page all-reviews link.
The export step is intentionally narrow: it reads visible review cards and writes one row per review. If review cards never appear, the current URL is skipped so the rest of the URL list can continue.
amazon-germany-review-scraper-mit-urls.csvColumn
produktnamen
Visible product name captured with each review row.
Column
produkt_url
Canonical Amazon.de product URL built from the ASIN when available.
Column
asin
Ten-character product identifier derived from the URL or page.
Column
durchschnittliche_kundenbewertung
Average customer rating text from the review or product page.
Column
anzahl_der_bewertungen
Visible total review count or filter-info text.
Column
benutzername
Reviewer display name.
Column
kundenbewertung
Review-level star rating text.
Column
titel
Review title after Amazon's nested spans are normalized.
Column
land
Country parsed from German review-date text.
Column
datum
Review date parsed from the same review-date string.
Column
inhalt
Review body text.
Column
anzahl_hilfreich
Helpful vote statement when Amazon shows one.
The JSON export is the workflow contract. The article explains the runbook, but the template page carries the current block graph, waits, selectors, and export configuration.
Runbook
How to scrape Amazon.de reviews by URL
Import the template
Open Amazon Germany Review Scraper with URLs, download the JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the bundled Amazon.de product links with approved product detail URLs. Keep only Amazon.de URLs when using this Germany-specific workflow.
Set the export path
In Structured Export, confirm the local save folder, file name, headers, and append mode. Use a project-specific folder so test runs do not mix with production exports.
Run one product first
Watch the browser move from product URL to review URL. If Amazon shows a prompt, handle it manually or stop the run rather than forcing volume.
Validate and scale
Open the CSV, compare several rows against the browser, then let the loop continue through the rest of the URL list.
Because the file mode is append, a rerun can duplicate rows. For clean tests, rename or remove the previous CSV before rerunning the same input URLs. For ongoing monitoring, keep a separate run log with URL list, date, locale, CSV filename, and any selector edits.
Validation
Validate the Amazon reviews to CSV export
Do not treat the first successful file as finished data. Sort the CSV by asin, benutzername, datum, and titel. Open a few product URLs from the file and compare the exported product context, star rating, review title, review body, date, country, and helpful vote text against the live page.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows for one URL | Validation page, CAPTCHA, unavailable product, no visible reviews, or changed review-card markup | Inspect the browser state, reduce volume, and rerun only after rows are visible. |
| Product URL exported but no review text | Structured Export ran before review cards hydrated | Keep the sleeps, add a longer wait, and rerun one ASIN. |
| Only the first review page exported | Amazon did not expose an enabled pagination Next link | Check whether the product actually has more visible pages in the current session. |
| Country or date looks wrong | German review-date wording changed | Update the parser for Rezension aus ... vom ... text. |
| Duplicates appear | Append mode reran the same ASINs | Dedupe by asin, benutzername, datum, and titel. |
Alternatives
UScraper vs Python, APIs, Octoparse, and hosted scrapers
There are several ways to approach an amazon reviews scraper by url workflow. UScraper fits teams that want a supervised local export, visible browser QA, and no scraper code to maintain. A Python scraper gives developers full control, but the team owns rendering, pagination, retries, selector changes, blocked pages, and CSV formatting. A hosted amazon review scraper API can be better when you need programmatic ingestion, contracts, and throughput, but it usually adds usage pricing and vendor data custody.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Analysts exporting approved Amazon.de reviews to CSV from known URLs | You still validate selectors when Amazon changes the page. |
| Python with BeautifulSoup or Playwright | Engineering teams that want code-level control | More maintenance around rendering, retries, parsing, and compliance. |
| Hosted scraper or API | Production ingestion and scheduled cloud runs | Vendor terms, usage costs, and data custody need review. |
| Octoparse-style no-code template | Teams comparing no-code scraper builders | Check where runs execute, how exports are stored, and how selectors are edited. |
If you are searching for an Octoparse Amazon scraper alternative, evaluate the workflow by custody, not only by UI. For small research jobs, a local CSV and an inspectable browser run are often easier to audit than a black-box cloud run. For large recurring pipelines, API contracts may matter more than manual review.
FAQ
Amazon.de review scraping FAQ
Amazon.de review pages can be visible in a browser, but automated collection may still be restricted by Amazon terms, robots directives, marketplace policies, copyright, privacy law, and local rules. Use only data you have a documented basis to collect, keep runs modest, and do not bypass CAPTCHA, sign-in walls, or access controls.
Next step
Download the workflow and run a small validation set
Use the Amazon Germany Review Scraper with URLs as the download path, then run one ASIN before adding a full URL list. For adjacent workflows, browse the full template library or read more UScraper tutorials on the blog.